Federated Learning: Building Privacy-Preserving AI Infrastructure
Why This Post?
At Eder Labs, for the last 6 years, I had been working on a fundamental problem in AI: how to enable machine learning on sensitive and personal data while guaranteeing privacy? The motivation for AI on personal data being advancing research, in biology, logistics, cognitive sciences, etc. and eventually building the infrastructure for a data oriented economy. I was 22 when I dropped out to work on this utopian ideal, and so I will write it with the same wonder.
As I am moving on to a different journey, I thought it would be a good idea to document my work, the technical and business aspects, and the lessons learned along the way.
We worked on privacy-preserving AI computation technologies like Federated Learning, Multi-Party Computation, and Trusted Execution Environments (TEEs). We raised $2M from Accel, built deep tech, worked with major enterprises, fintech and defense tech teams and navigated a constantly shifting market landscape.
This post focuses on the technical journey, specifically Federated Learning, detailing how we built a privacy-preserving AI infrastructure. I will write a separate post on TEEs, as I believe confidential computing and on device AI hold the key to unlocking personal data for the LLM revolution.
Federated Learning: Decentralized Model Training Without Moving Data
Traditional machine learning requires gathering vast amounts of data in a centralized location for training models. This approach, however, presents fundamental issues in scenarios where data is sensitive, private, or simply cannot be moved due to regulatory and logistical constraints.
Federated Learning (FL) is the solution to this problem. Instead of bringing data to the model, we brought the model to the data. The core idea was simple: distribute a global model to multiple client nodes, let them train locally on their private datasets, and aggregate their updates into an improved global model—without ever transferring raw data.
1. Early Experimentation and TensorFlow.js
Our first implementation of FL was a browser-based prototype using TensorFlow.js. The goal was to allow personalized models to be trained on-device, directly in the browser, without requiring any installations or sending data to external servers.
We leveraged WebAssembly to execute TensorFlow operations with near-native speed and WebGL to access GPU acceleration in supported environments.
However, we faced critical limitations in deploying TensorFlow.js effectively for real-world FL tasks:
-
WebAssembly (WASM) Backend Challenges:
- Lack of SIMD support hindered parallelism and made operations like convolution slow
- Operations such as
tf.conv2dproduced inconsistent results compared to CPU and WebGL backends, affecting reliability
-
WebGL Backend Challenges:
- Shader programs were compiled lazily on the main thread, causing latency on first-run
- GPU resource contention made inference times unpredictable when used alongside animations or other GPU-bound tasks
- Browser background tab policies suspended training, making uninterrupted federated learning infeasible
-
General Browser Limitations:
- Inconsistent threading and performance across Chrome, Firefox, Safari
- Storage limits with IndexedDB made local dataset handling hard
- Security sandboxing made full-stack instrumentation and debugging difficult
Despite these challenges, we built a lightweight federated learning proof-of-concept that allowed users to upload their personal photos, label them, train locally, and contribute model updates—all in-browser.
We could successfully load MobileNet and Coco SSD and train them in a federated way in chrome browser across laptops, windows, iOS, linux, and android phones as well.
We built on TensorFlow.js’ Layers API and compiled shader-based kernels for acceleration. But scalability remained a concern, especially with model convergence speed and user device heterogeneity.
Apart from the technical and resource limitations, the user experience was awful for real life applications. The main reason being the model loading time at the initiation, and the handheld devices would heat up quickly in few iterations.
2. Scaling Federated Learning to Enterprise Use Cases
Realizing that browser-based training had limitations, we evolved our architecture to support edge computing environments where federated learning could be deployed on powerful client devices, enterprise servers, and embedded systems.
This required designing a Federated Learning Coordinator that orchestrated training across multiple client nodes, ensuring privacy while improving model accuracy.
The product was called Fluid. The idea was that intelligence could flow freely between organizations, entities, and individuals without the risk and costs of moving the data.
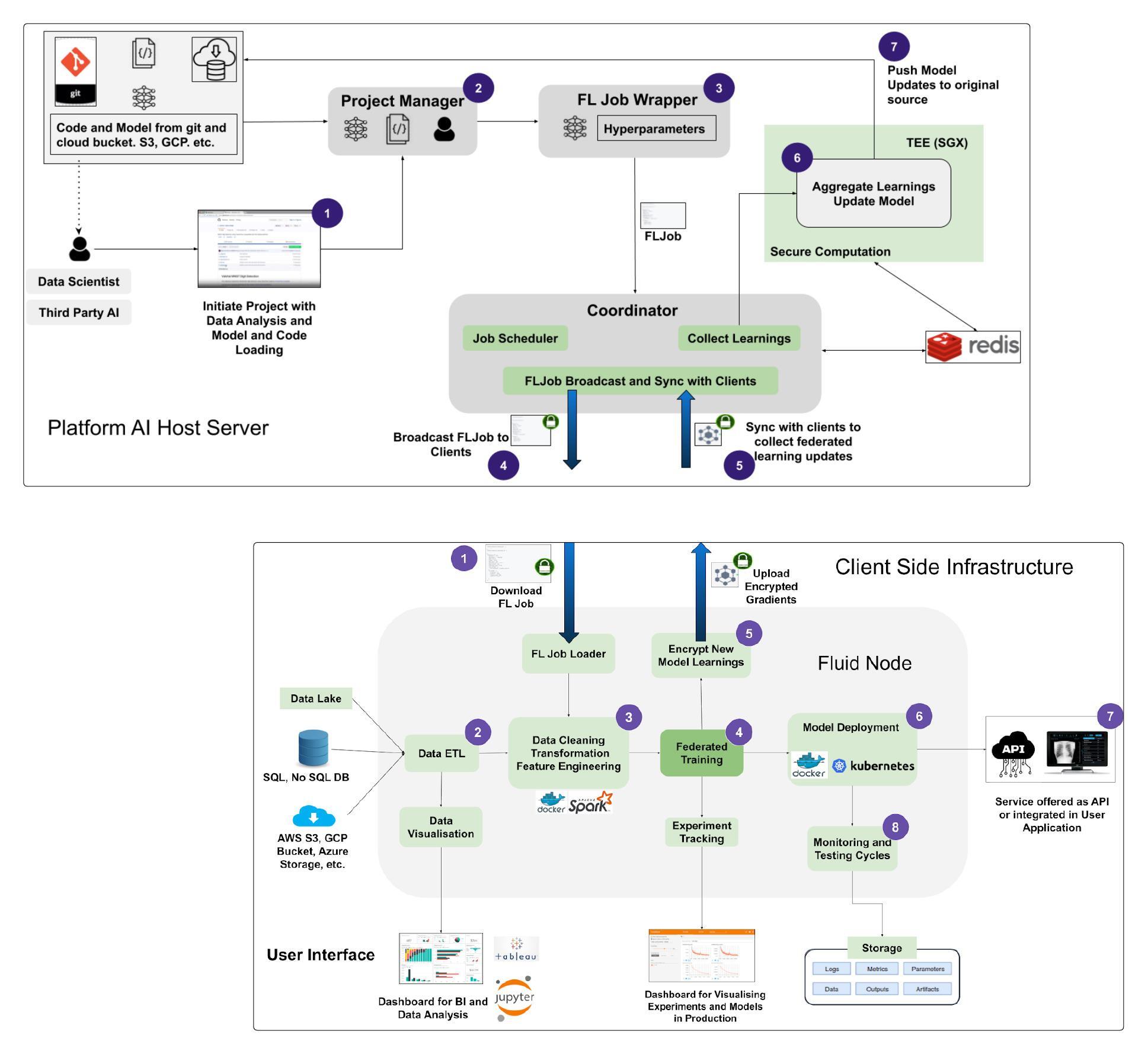
Our final architecture had three core components:
-
Client Nodes – These were responsible for local model training using on-premise data. Clients received the global model, trained it on their datasets, and sent encrypted updates back.
-
Federated Learning Coordinator – This central service aggregated model updates using secure aggregation protocols to ensure privacy.
-
Aggregation Server – Instead of naively averaging model updates, we implemented secure multiparty computation (MPC) technique to ensure that no single party could reconstruct private training data. We implemented this more out of curiosity and beauty of the idea, but this was too slow and impacted accuracy, so we instead secured aggregation by performing it in a Secure Enclave.
This allowed us to train machine learning models across multiple hospitals without moving patient data, across financial institutions without sharing customer details, and in defense applications where data sovereignty was critical.
But that’s the just the training layer and the cool part of solving the problem. Most of the enterprise use cases have to perform the entire life cycle of developing an AI solution.
- Access to Data following Regulations and Compliance
- Exploratory Data Analysis
- Modeling (Training)
- Deployment (Inference)
This is broadly what MLOps was, and we were specializing MLOps for sensitive and private data.
The kind of use cases where organizations had to collaborate to explore new possibilities emerging from their data, but were not willing to share the data.
I will briefly mention how we built for the entire Privacy AI MLOps stack and then get back to Federated Learning for a deeper dive.
-
Access to Data: This is essentially a data movement problem, with additional requirements for data privacy and compliance because the source and destinations are two different organizations with difference CISOs responsible for the security, integrity and regulatory compliance.
So we took a popular ETL tool, broke it apart. And applied a layer of PII tokenization on the source, and de-tokenization on the destination where needed. It’s a standard, that most orgs agreed to and is essentially compliant with most healthcare and fintech regulations in the US market.
-
Exploratory Data Analysis This is where it gets interesting, the data owners don’t want their data to even sit idle at the collaborating party, so they need a clean room like interface with guarantees that the third party data scientists will only be able to perform EDA on the data temporarily, and the data stays locked after that even if it stored on the third party systems. We leveraged Confidential Computing to create such data clean rooms and provided cryptographic guarantees. I will describe this in depth in the second post, focused on TEEs.
-
Modeling and Training The modeling experiments conclude as a training job, with architecture, hyper-parameters, and the set of locations where the data sits. We called it FL Job, and this would then be responsible for orchestrating the system that would carry out the federated training. We dive into this aspect in detail through this post.
-
Deployment (Inference) If we can train in a federated way, then federated deployment is a no brainer. We would collect the inference logs, and send them back for analysis, versioning, etc. The standard MLOps Inference tasks.
Fluid’s Architecture in Plain English
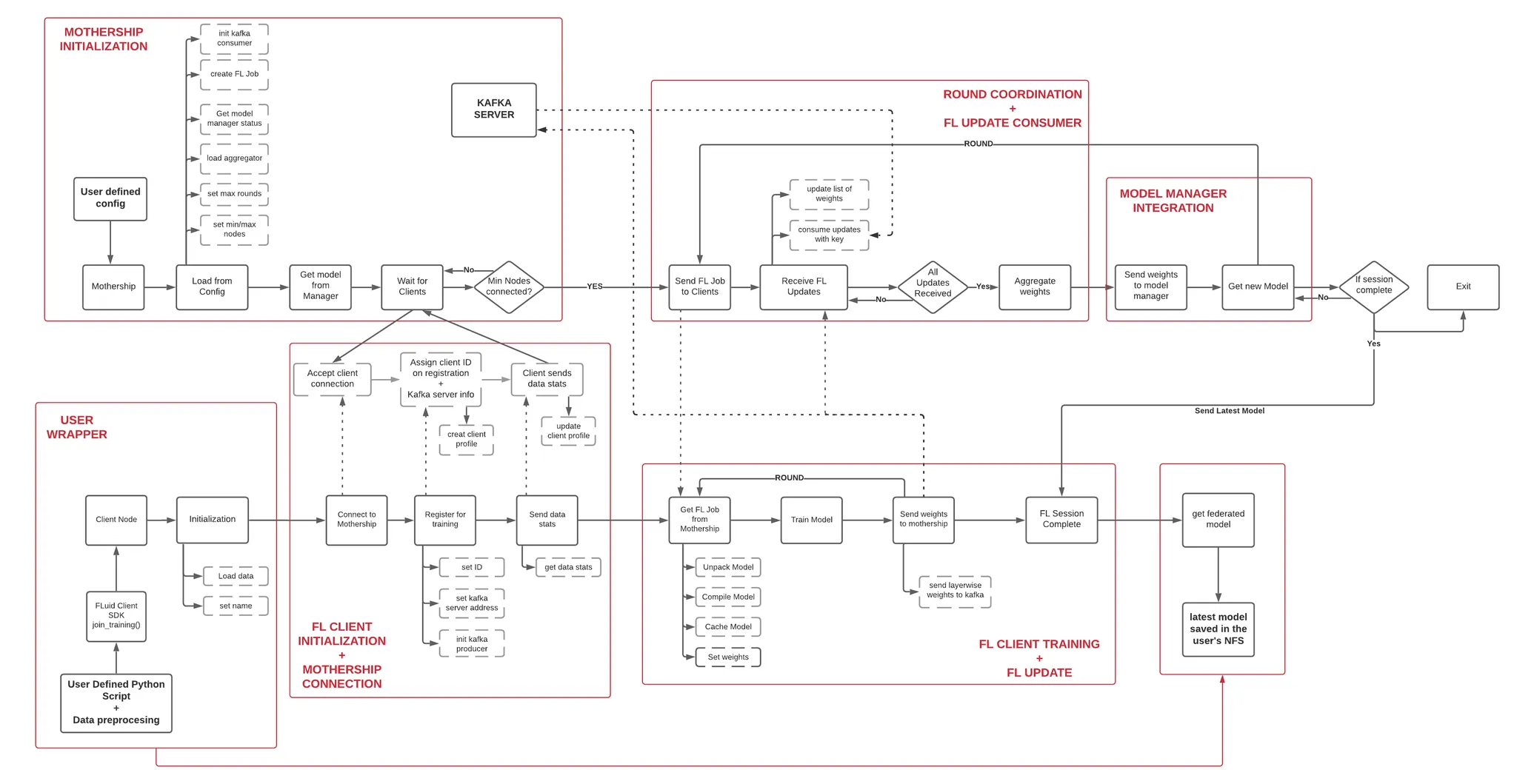
TL;DR: Mothership coordinates, Clients train, Kafka moves tensors, and Model Manager keeps score.
1. Mothership (Coordinator)
- Single Docker container that boots with a YAML config (
fl_conf.yaml) - Exposes a Socket.IO server; clients register, get a session-scoped ID, and enter the “train room”
- Maintains three dictionaries:
active_nodes,inactive_nodes,training_nodes, plus apending_listfor whatever clients still owe an update this round - Starts the next round when
len(active_nodes) >= min_nodes. Emitsstart_trainingwith a model binary + hyper-params attached
2. Client Node
- Tiny Python SDK:
fc = FLClient(name="node_1", mothership="10.0.0.12:8080")
fc.join_training()
- On
start_training, it downloads the model, trains locally (Keras/TF only in v0.1), chops weights into layers, and streams them to Kafka with itsclient_nameas the key - Sends a lightweight
fl_updateACK so the Mothership can tick it off thepending_list
3. Kafka Transport
- We used HTTP-polling for the control plane (Socket.IO) but Kafka for the data plane so we could blast 100 MB models without choking a WebSocket
- Layer-wise messages let us resume or retry a single shard if the connection hiccups
4. Aggregator Plug-ins
- Strategy pattern (
get_aggregator(strategy="weighted")) - Naive, Weighted by sample count, and (planned) Gradient variants
- Every aggregator enforces “shape sanity”—if one client uploads a weight tensor that doesn’t match, the round aborts with an
AggregationException
5. Model Manager (Confidential Scorekeeper)
- Wrapper around MLflow -> MySQL (+ NFS artifacts)
- After each round:
- Reconstruct model from aggregated weights
- Evaluate on a hold-out set inside an SGX enclave (when TEEs were in play)
- If
new_metric > primary_metric, promote the version and emitmodel_improved
6. Event Bus & Dashboard
- Every significant action (
session_start,round_end,client_disconnected, etc.) becomes a JSON event on afeedKafka topic - A WebSocket proxy streams those events to the front-end so ops folks see live logs, metrics, and node health without SSH-ing anywhere
Why it was novel (for 2021)
- No enterprise grade off-the-shelf cross-silo orchestrator in the open source tooling. Mothership with Kafka rooms was a mature FL orchestration system
- Model versioning chaos was taken care of by an MLflow backed Model Manager
- Secure Metric Evaluation with SGX Enclaves/Nitro Enclaves
- Unified event bus granted real time UI for observability
What I still like about this design
- Decoupled transports: control traffic over Socket.IO, heavy tensors over Kafka. Even modern Flower/FLARE adopt a similar split
- First-class logging: every round, node, and metric is an event—perfect for audit trails
- Plug-able everything: new aggregator? new TEE? Drop-in without rewriting the coordinator
Prototype Spotlight — ESPnet + Federated Learning (2020-21)
In mid-2020 a defense customer posed a challenge uniquely suited to our stack:
“We need speech-to-text for six under-documented dialects. The audio lives on forward bases with patchy VSAT links, and we can’t export a single waveform. So we have to train the model out there and still get it to improve.”
This kicked off many months long setup that married ESPnet with the still-under-construction Fluid FL stack. ESPnet is a end to end speech processing toolkit with a healthy ecosystem. We were using only the ASR models and the self supervised learning pipeline for our federated setup.
The setup
- Seed model – a pruned Conformer/Transformer from ESPnet, pre-trained on Librispeech (≈ 80 MB after weight-sharing and gzip)
- Edge fleet – five Intel NUCs, each plugged into a single NVIDIA T4 eGPU and running Ubuntu 18.04
- Data reality – about 60 hours of raw audio per site, but only 4 hours per site had honest-to-goodness human transcripts
- Topology – Socket.IO for control traffic, Kafka for weight shards; one on-prem “Mothership” orchestrator, five FL clients
- Training cadence –
epochs = 1,batch = 8, three federated rounds; each round pushed ~70 MB of layer-wise weights per node
What happened
- Round-0 baseline – local fine-tune without FL delivered a Word-Error-Rate (WER) of 31% on a 2-hour dialect test clip we were allowed to copy
- After 3 FL rounds – the aggregated model dropped WER to 24% (a 7pp swing) and dev-set loss fell roughly 15%
- Proof points – weight aggregation matched a centrally-trained control run on synthetic data, and Kafka never dropped a shard
Where it cracked
- Label starvation – < 10 h of gold transcripts across the entire corpus; future rounds would stall unless annotation ramped up
- Thermal throttling – the fan-less NUCs hit 90 °C after 45 minutes, halving training speed
- Governance wall – legal blocked export of any new labelled clips, so long-term WER tracking was impossible
Since this was a sensitive and an urgent deployment the customer went with the first successful deployment. We could have done a lot better experimenting with SSL.
How we’d make it production-worthy today
- Self-supervised pre-training – start from wav2vec 2.0 or HuBERT so each node needs only minutes, not hours, of labels. And build the federated pipeline for this instead of a pre trained model
- On-device “tap-to-approve” UI – let operators validate high-confidence pseudo-labels during downtime and feed them straight into the next round
- INT8 + fp16 mixed precision – halves thermal load and shrinks per-round uploads under 30 MB
- Asynchronous FL – let nodes train whenever temps are low; aggregate whenever two or more updates arrive
- Top-K gradient compression – chops satellite bandwidth without hurting convergence
- Ephemeral SGX enclaves for eval – keeps any shared reference set encrypted in memory while still giving programme managers real WER numbers
Take-away: the networking and aggregation code held up fine; the bottleneck was labelled data and edge hardware limits.
Lessons Learned
Technical pain
- Device heterogeneity Running the same Docker image on a fan-less Intel NUC, an SGX-capable Xeon, and a random GPU workstation is not “write once, run anywhere.” Kernels, CUDA toolkits, even glibc versions fought us
- Enclave limits Intel SGX gave iron-clad privacy—but the 128 MB EPC meant constant page-swapping. We spent more time sharding models than tuning them
But honestly, technical challenges were most welcome, because we built that kind of culture. Most of our pains and learnings were on the Go to Market side. The operations. The people, behavioral psychology. That is where the great technical possibilities go to die, and pragmatic co-founders are born.
Go-to-Market pain
- Enterprise fear cycle Each pilot required a new DPIA, a new security review, and board-level sign-off. Sales cycles stretched past 12 months—longer than our startup runway
- Security and Ego Every proposal for accessing and using data by a PM would be taken to a CISO who would not want to learn any new technology, and would instead prefer to maintain the status quo
- Multiple Stakeholders The default assumption in decentralized, multi party collaboration is that there are multiple stakeholders who are willing to work together for a shared outcome and mutual benefits. It is rarely the case, and turns into corporate politics theatre very fast
- Virtue Signaling Privacy is not an urgent problem to solve, it’s a nice problem to talk about. We found that many large hospital chains, were openly sharing sensitive patient data across google drive, even if limited and bottlenecked by quantity. But would stay complacent for new innovation to be done on that same data because it would require new ops
The Problem Space, Then vs Now
Back in 2018-21 the FL landscape felt like the wild west. PySyft demos were cool but mostly academic; TensorFlow Federated was still a research playground (it still struggles with GPU support today); and there was no drop-in, cross-silo infra that an enterprise dev team could spin up in a weekend. If you wanted to federate data that lived in half-a-dozen Postgres instances behind firewalls, you essentially had to build your own coordinator, transport, and model-versioning stack from scratch.
Fast-forward to 2025 and an entire tooling layer now exists:
- Flower 1.x ships with
ServerApp/ClientApp, PyTorch + TF quick-starts, ViT and MONAI medical examples, and even a Vision-Transformer-over-federation recipe - NVIDIA FLARE 2.x gives you an “industrial-grade runtime” with PEFT/LLM fine-tuning and HIPAA-style security baked in
- The two stacks are actually converging—Flower clients can now run natively on the FLARE backend without code changes
In other words, today you can “pip install flower → docker-compose up” and have a production-ready FL server with TLS and dashboarding. In 2021 we had to invent all of that plumbing ourselves—Kafka topics for weight shards, Socket.IO for control traffic, MLflow for model versioning, and hand-rolled secure aggregation.
That context matters: our design decisions look heavy-handed only because the open-source ecosystem caught up later. The problems we solved (cross-silo orchestration, audit-grade logging, model lifecycle management) are exactly what modern frameworks pride themselves on today.
Closing Thoughts
Over the years, we built an end-to-end privacy-preserving AI infrastructure that combined the best of Federated Learning and Trusted Execution Environments. From browser-based federated learning to secure edge deployments and SGX-based confidential AI computation, we pushed the boundaries of what was possible in privacy-first machine learning.
While the technology was promising, challenges in enterprise adoption, performance trade-offs, and infrastructure complexity ultimately made widespread deployment difficult. However, the need for privacy-preserving AI is more relevant than ever, and we hope our work serves as a foundation for future innovations.
Note: This is Part 1 of a two-part series on building privacy-preserving AI infrastructure. The next post will cover Trusted Execution Environment and how we built clean rooms for secure data exploration.