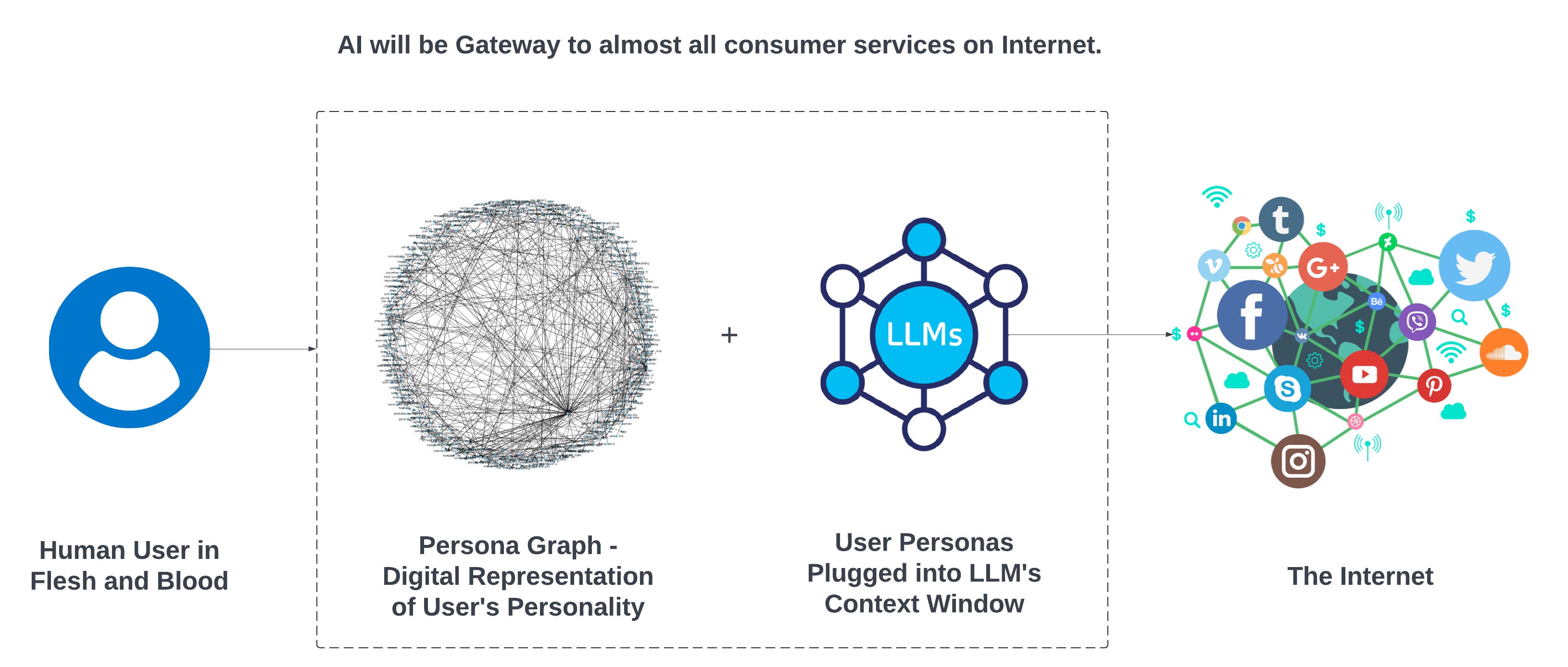
Persona Graph: Intelligent Identities for an Intelligent Internet
Introduction
In the era of content explosion and attention economy, personalization is the most important piece for a healthy internet experience. Whether it’s in our awareness or not, what we need to move forward in our life already exists on the internet, it’s just a matter of discovering the right links. However, multiple influencers on digital platforms combined with standard doomscrolling algorithms from 2010s, internet experience is more dystopian today than the utopia it was designed for.
But with AI advancements in language intelligence, there’s an opportunity to solve this problem and evolve the average internet experience. We need to design more human centered personalization and recommendation systems. The entire internet after all, is a giant information recommendation system. And all good recommendation systems need a great user representation. We can start laying the groundwork for a holistic user identity system, and LLMs are here to aid us.
Here’s what I propose. The digital identity of the future should be a user owned personal knowledge graph, where each meme is a node, connected with other memes through relationships forming a personal web of the user’s memetic complex. The graph should be user owned, changing states across time, and evolve like an organism as the human behind it evolves.
In this article I will:
- Touch on the concept of identity, memory and memetics
- Introduce the concept of persona knowledge graph and the design principles to construct one
- Share practical insights on why I am bullish on knowledge graphs for memetic representation and why “simpler” data structures won’t cut it
I am sharing a basic library to kickstart your own implementation. Check the library here: https://github.com/saxenauts/persona
Need for a memetic representation
Digital services across the internet, and those interacting with the physical world make use of data to derive a picture of a human. A simple impression is enough for simplest of the use cases, for ex. Name, Age, Location, Gender, suffices most services. As the services get complex, they need more data points to define the human they are serving. For example:
- Health Insurance companies need a lot more personality vectors like - medical history, habits, work and lifestyle, responsibilities.
- A specific digital service like Steam or Netflix will store a list of tags relevant to the service like - genres, actors/directors, franchises, language, etc.
- More complex and general digital content recommendation service like Instagram / X / Pinterest stores a list of tags, social graph, of the interests to create a picture of their users.
- State of the art for most recsys today at their technological core is machine learning based recommendation models, and the human representation for that technology is in User Vector embeddings. GraphSAGE, and others.
We have now entered the age of LLMs, state of the art is converging to language intelligence — language input, language output — abstracting away all the deep neural network alchemy. It follows that most services in future will have a language component in their interaction layer. And so it seems right to design a framework that can represent a complete digital holistic identity of a human.
Memetics, Memory and Identity
Carl Jung once said, “People don’t have ideas, ideas have people”. This is a beautiful interpretation of memes and the power they hold over groups of humans.
Understanding Memes:
Richard Dawkins coined the term. Memes are to our minds what genes are to our bodies. The combination of personal stories, tags, ideologies, aesthetics, cults, movies, legends, religion and symbols we associate ourselves with is a broad definition of memetics / memeplex. The ideas that propagate within our psyche and culture form the basis of this memeplex.
Core Characteristics of Memes:
- Replication: Memes spread through imitation and transmission, evolving as they pass from mind to mind
- Adaptation: They modify themselves to fit within existing belief systems and cultural contexts
- Persistence: Strong memes survive by remaining relevant and memorable, while weak ones fade away
Identity, memory and memetics are intertwined. Our Identities are shaped by the ideas we adopt and remember. Memory forms where the attention is directed. These are loose concepts and not defined concretely in the literature, and so I will carry the tradition and treat them loosely.
Understanding Memory:
- Identity Formation: Memory is integral to our identity—we are, in essence, what we remember.
- Relevance and Adaptation: Memory helps us navigate our life path by retaining relevant information and discarding the irrelevant, enabling decision-making and adaptation.
- Dynamic Nature: It is dynamic, self-organizing, and continuously evolving, mirroring our experiences and interactions.
Functional Pillars of Memory:
- Novelty: Capturing new and surprising information external information that enhances our perspective.
- Repetition: Reinforcing information through repeated exposure, aiding recall and inference.
- Forgetting: Letting go of irrelevant or outdated information to optimize cognitive resources.
- Knowledge generation: Internal mapping and remapping of disconnected concepts for new knowledge of organism’s self.
The Synthesis: Memes, Memory, and Identity in Digital Space
The intersection of these three concepts forms the foundation for the digital persona framework:
- Modeling Identity: To capture our identity is to capture our memetics, is to capture our memory.
- Memory Dynamics: These memes are maintained through memory mechanisms—strengthened through repetition, expanded through novelty, and refined through forgetting.
- Identity Evolution: The resulting system naturally evolves as new memes are incorporated and outdated ones fade, creating a dynamic digital representation of personal identity.
This is sufficient and simple enough to start designing a language-based user memory agent, or a human memeplex. By aligning our digital persona with these principles, we can create a system that not only stores information but also evolves and adapts like human memory, reflecting the natural processes of natural evolution. This digital organism should then be the perfect reflection of our informational representation.
Designing the Persona Knowledge Graph
We intend to model the identity of a user through knowledge graphs. While the underlying graph theory is well-established and accessible, the innovation here is in the system design: integrating personal knowledge graphs and large language models, viewed through a memetic lens and enhanced with dynamic update mechanism.
Design constraints
- We will only work with context window to inject user personality in LLMs. No parametric or architectural changes to LLMs, although there is good work happening there.
- Start designing from first principles basis, as we enter a new age of internet. We will not think of optimization and costs relative to the industry standard baggage. This is new work, for a new age, so please allow yourself and me a suspension of disbelief, the ecosystem and constructive feedback will solve the optimizations as we work on this.
- This is not for a conversation specific design, but for general purpose LLM use and personalization beyond LLMs. This can be used for conversational RAG as well. We will need to do smarter benchmarking to compare both approaches.
I - Building Blocks
1. Memes as the Fundamental Units
- Personalized Memes: Each meme is a unique unit tailored to the individual. Meme in this framework could be single words, labels, phrases or even sentences, because this is where the language and personalization takes it core.
- Examples:
- “Rock music”
- “Civilization, rise and fall”
- “Orange is the right kind of juicy.”
- “Cafe Racer aesthetic”
- “Hyperspace and fractals visualizations come natural to the mind”
- It’s important that the fundamental units can be either fully formed expressions unique to the user, or tag like phrases common across the culture. This should come organically from individuals, as every experience is unique, every expression is unique.
- Examples:
2. Nodes and Relationships
- Nodes: Represent individual memes or ideas.
- Relationships (edges): Show connections between memes, indicating relationships like influence, similarity, or hierarchy between different memes. This is where things become a lot more personal to the human.
- For example, “Cafe Racer aesthetics” might link to “Old school design” for person A; “Tom cruise in Maverick” for person B, and “Road Rash” for person C. It doesn’t matter who is factually right or wrong. We all form our own realities, and should be allowed to stitch our own memetic webs.
3. Nodes and Relationship Properties
Node: Each node in the graph comes with specific attributes:
- Content: The core idea or statement of the meme.
- Activation Level: How prominent or relevant the meme is currently.
- Associations: Links to other related memes.
- Timestamp: When the meme was added or last updated.
- Frequency: How often the meme is activated or comes up.
- Qualitative Measure: Personal preference rating or aesthetic value. This can be used for user’s interference, or programmatic interference to the graph state.
Relationships: Relationship can have a limited category type, and attributes:
- Types: Constraining the relationship to types, affords more variance in nodes.
- Hierarchy: A logic set on type that limits the hierarchy from seed nodes to desired depth
4. Semantic Indexing with HNSW
-
Hybrid Model: Storing the memes’ as embeddings in a vector index is a crucial and complementary component of our persona graph. It afford us all the good things of RAG, which in our context implies vector search, semantic mapping, establishing new connections, clustering, etc. Works like memory, works like magic.
-
HNSW Index: Each meme’s embedding is indexed in a Hierarchical Navigable Small World (HNSW) index. HNSW creates a graph (albeit a different kind), and the associations in the index can be ported to the knowledge graph as well, CozoDB follows this approach. I haven’t yet bothered to check if other indexing techniques work better, but it makes sense from a bird’s eye view.
-
We are storing facts as structured data, or assuming that facts are stored in language. Cosine similarity is not a good substitute for plain old fact retrieval. Two semantically similar vectors convey little information about the actual memory, but do point in the right direction.
II - Graph Construction
5. Constructing the Graph with LLMs
-
Unstructured Data Processing: We use LLMs to sift through personal content—like journal entries, social media posts, or browsing history, emails, or any other data. Preprocessing pipelines can be made for each. For my product at my startup, we are processing posts from X, Youtube, and Gmail integrations with a custom processing layer, then it is fed to the graph.
-
Meme and Relationship Extraction: The LLM identifies key ideas and statements that resonate with the individual. Here’s a survey of graph construction techniques using LLMs. Another article with good examples.
-
Graph Schema in Prompt: A standard graph construction prompt will work in most cases. However, it would be ideal and a huge performance boost if some core component of the user’s psyche can be provided as context to the graph construction prompt. So we will represent user’s psyche as ontologies, and providing a graph schema in the prompt dynamically.
6. Updating the Graph
-
Injecting Nodes and Edges: After LLM construction step, newly discovered memes and their connections are added to the graph. I am using standard cypher queries for text matching and graph updates. Please check the code for reference.
-
Parameter Adjustment: Old memes detected, or similar memes detected can directly be injected into the graph. This updates frequencies, weights, and other node properties.
- Repeated mentions increase frequency counts.
- Strong associations boost edge weights.
- Update the timestamp of the node, as well as it’s parent nodes.
- Activation function dependent on the above parameters.
III - Designing System Functionalities
7. Retrieval Using RAG-like Queries
-
RAG Queries: When information is needed from the graph, a RAG query is made. From the primary query, we can model a secondary query on the basis of graph schema, and this in our context becomes a simple implementation of “ask anything about the user”
-
Additional Relevant Context: Semantic queries, or graph queries will hit top-k nodes, and these nodes can be crawled further to find more associations to add to the context of our generation stage. This advantage is graph structure specific. Because co-sine similarity is not a good proxy for fact storage, but a data structure is.
8. Knowledge Generation
-
Similarity Scores: By analyzing how closely memes are related, the system can generate new insights. Using similarity search, spread out search, multi hop connections can be established.
-
New Connections: It might discover that the meme “Fitness is about gravitational balance” relates to “Mindfulness practices,” suggesting a new area of interest. It might discover that “Adventure Biking” is related to “Nature, Hikes and Trekking” and connect with “BMW R 1250 GS”. Seemingly disconnected topics will find more relevance, and open up new connections.
-
Subgraphs, Communities and Clusters: Identify clusters groups from HNSW, or through graph analysis, and generate new nodes and relationships to better label and connect these concepts. Eigenvector Centrality and PageRank can be used to define the influential nodes.
9. Forgetting Mechanism
-
Activation Decay: Memes not activated over time decrease in activation level. This can be a simple logarithmic function. I have found a Forgetting Constant in a time-state model to be a simpler implementation that works. However I believe a log decay will unravel the true beauty of forgetting.
-
Edge Weight Decay: Connections can decay over time imitating our memories.
-
Dynamic Adaptation: This ensures the graph stays current with the individual’s evolving identity. So prominent nodes can be taken over by their subnodes. For example. FPS gaming is less important than Counter Strike, for a hard core CS player.
10. Psyche Analysis Functions
-
Inference of New Memes: Specialized functions analyze existing memes to uncover underlying themes. This can be use case focused functions designed by the experts. Or even be user defined functions for more self aware users.
- System can be designed to identify ideological, aesthetic insights from existing memes.
- Detect anomalies, or change in personality traits over time.
- For example, for a therapy app, the psychologists behind it can ask the agent to follow any psychology ontologies, but for a traditional system like Advaita, or Tao, the ontologies could look very different.
-
Defining a core psyche: This idea seems very interesting to me, because of the emergent possibilities from it. To design an agent that constantly monitors the state of the graph, and detects nodes or adds new nodes and define these as core psyche of the individual.
- Like above, with knowledge generation, this can be done with cluster analysis, community detection, eigenvector centrality using activation level. Or more advanced graph algorithms.
- I personally would love to see a set of core beliefs and psyche that remain constant through time but generate new memes from it, that are spiral / fractal in nature. This is where it gets mumbo-jumbo, and I will wait for when the system is in action and deployed at scale.
IV - Function Definitions
Functions for graph updates are laid out in the screenshot below. I am working on a more elaborate paper and will share it in future posts. For now, here’s a one pager.

Bringing It All Together
Our persona graph is:
- A Living Representation: It grows and changes as the individual does. It lives and breathes data as you live and breathe. Not just who you are, and have been, but also who you are becoming.
- Deeply Personalized: Every node reflects something unique about the person. And editable with raw language, and visible and transparent to the users.
- Interconnected: Relationships between memes mirror the complex web of thoughts and beliefs.
- Enhanced by LLMs: Leveraging advanced language models to enrich and maintain the graph.
- Functionally Rich: Supports retrieval, knowledge generation, and even self-discovery.
First Principles Consideration
Graph Theory vs Set Theory - Why it can’t be a list of lists
When developing this framework I was asked questions on the choice of database, and why did I choose graph when other traditional databases are much simpler. For example, I could have chosen a list of lists, it could have been a Relational DB, Document DB, Key-Value stores, Interest Trees etc. So then, why graph? I will explain my perspective here.
We are building the memeplex, and we need to model the complexity of human mind, changing patterns, and living experience. We need to build foundations for quantified self models, because the memeplex has been the missing piece so far in all quantified self movement. We are not just numbers, we are numbers associated with symbols.
Typically, most data structure choice comes down to some variant of set theory or graph theory. Graph theory emerges as the superior choice for modeling human memory and enabling advanced personalization. Here’s why.
Graph Theory and Human Memory: Natural Alignment
Graph theory models data as interconnected nodes (entities) linked by edges (relationships). This structure closely resembles the way human memory operates. There’s been multiple research on modeling brain activity with graph theory:
1. Interconnectedness Mirrors Human Thought
- Associative Memory: Human memory is highly associative; one thought leads to another through a complex web of connections. Graphs naturally represent this by directly linking related concepts (nodes) via edges (relationships).
- Example: Thinking about “rock music” might lead you to “electric guitars,” “concerts,” or “favorite bands.” In a graph, these connections are explicitly modeled, allowing for seamless traversal between related ideas.
2. Dynamic and Evolving Structure
- Flexibility: Graphs allow for the easy addition or removal of nodes and edges without restructuring the entire system. This mirrors how our memories evolve with new experiences and information.
- Adaptability: As your interests change, the graph can adapt by strengthening new connections and weakening outdated ones, simulating the natural forgetting process.
3. Efficient Traversal and Retrieval
- Quick Navigation: Graph algorithms enable efficient traversal through related concepts via multi-hop connections. This is akin to how we recall information by following associative paths in our minds.
- Advanced Queries: Techniques like Breadth-First Search (BFS) and Depth-First Search (DFS) facilitate complex queries, such as finding indirect relationships or the shortest path between concepts.
4. Facilitates Knowledge Generation
- Emergent Insights: By exploring different paths and connections within the graph, new insights and knowledge can emerge. This aligns with human creativity, where combining existing ideas leads to novel concepts.
- Community Detection: Graph algorithms can identify clusters or communities within the data, revealing underlying themes or interests that may not be immediately apparent.
5. Built-in Forgetting Mechanisms
- Edge Weight Decay: Less relevant or unused connections can be weakened over time by decreasing their edge weights, simulating the forgetting process.
- Activation Levels: Nodes can have activation levels that decrease if not reinforced, ensuring that the most pertinent information remains accessible.
Limitations of Set Theory and Document Databases
1. Lack of Explicit Relationships
- Disconnected Data: Set theory treats data as collections of independent items, lacking inherent relationships between them.
- External Complexity: Any relationships must be imposed externally, often resulting in complex and impractical queries, requiring human intervention.
2. Flat and Static Structure
- Rigidity: Without inherent links, modeling dynamic and evolving relationships is challenging.
- Inflexibility: Adapting to new information requires significant restructuring or complex indexing.
3. Inefficient Retrieval of Related Information
- Resource-Intensive Searches: Retrieving interconnected data requires extensive searches or additional indexing.
- Performance Bottlenecks: As data grows, queries become increasingly resource-intensive, hindering real-time personalization.
4. Limited Knowledge Generation
- Insight Constraints: Discovering new relationships or patterns is difficult without explicit connections.
- Static Insights: The system lacks mechanisms to naturally combine existing information into new insights.
Graph Database with Vector Database is ideal for designing memories. We will optimize for costs, latency and scale as and when the need comes.
Conclusion
We discussed persona graph, and the need for building a memeplex for every human on the internet. We discussed why personalization technology needs to become more holistic, and language oriented. We understood the system design for building this identity system. But we haven’t discussed how this works in an information recommendation scenario.
In the next article I will write about building recommendation and information filtering systems with persona graphs. This is also a product I have been building at my startup, and I am now moving ahead in this journey and finding a new home for this work. Building next gen personalization is not just about the technology and modeling, but the user interaction design as well. All of this for the next article.
Alright let’s wrap this up. Three takeaways here.
- Persona Knowledge Graphs are the future of personalization. Let us put some hope in memetic modeling and emergent data structures.
- Graph beats traditional data structures hands down. And this works very well with semantic search and LLMs.
- The time is right to build a memetic personal framework, and not just save the internet, but evolve it, let it breathe and thrive.
I have been working on this concept for about a year, have only recently begun to draft this. The library I linked is basic, and under MIT License, please reach out to me at saxenauts@gmail.com, and help me carry this research out, or break it apart with a better model.
The goal is to move toward a more human personalization for an information rich future while preserving our attention - the only thing we really have.